Documentation Index
Fetch the complete documentation index at: https://support.entegrata.com/llms.txt
Use this file to discover all available pages before exploring further.
Overview
Running a pipeline executes all configured data type mappings, pulling data from your Collector sources and loading it into your Entegrata data warehouse. Pipelines can run manually on-demand or automatically based on configured triggers.Execution Modes
Entegrata supports two pipeline execution modes:Standard Run
A standard run executes the pipeline and writes data to your production data warehouse. Use this for:- Production data processing
- Scheduled automatic executions
- Final data loads after validation
Dry Run
A dry run executes the pipeline logic without writing data to the warehouse. Use this for:- Testing new pipelines before deployment
- Validating field mappings
- Troubleshooting errors
- Verifying source data quality
Always perform a dry run before deploying a new pipeline or after making significant mapping changes. This helps catch errors without impacting production data.
Running a Pipeline Manually
Navigate to Pipeline List
Log in to the Entegrata Admin Portal and go to the Pipelines tab.

Check Pipeline Status
Before running, verify the pipeline status:
- Draft: Pipeline must be deployed before running
- Deployed: Ready to run
- Running: Already executing (wait for completion)
- Paused: Can be run manually even when paused
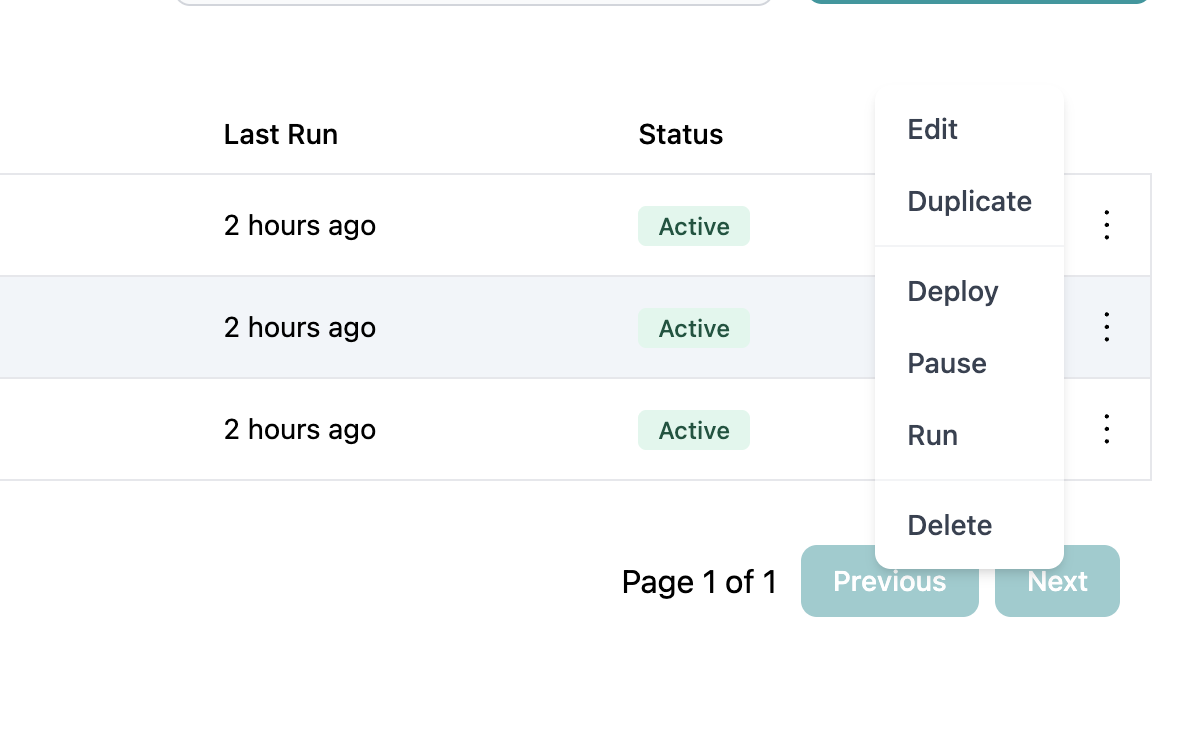
Select Run or Dry Run
From the actions menu, choose:
- Run - Execute with data writes (production run)
- Dry Run - Execute without data writes (test run)
Confirm Execution
After selecting Run or Dry Run, the pipeline execution begins immediately. You’ll see:
- Success message confirming the job was queued
- Pipeline status changes to Running
- Execution start time is recorded
Monitor Execution
While the pipeline runs, monitor its progress: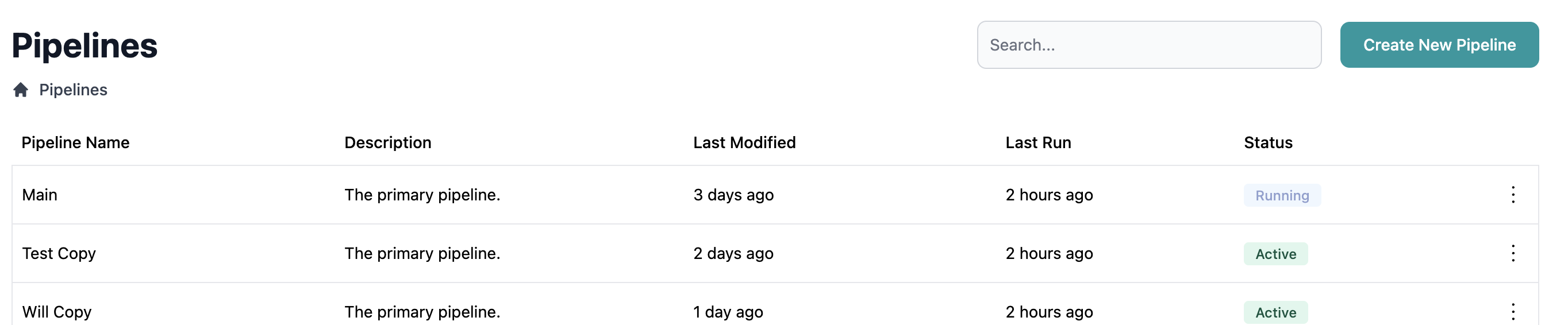
- Status badge shows “Running” with progress indicator
- Click the pipeline name to view detailed logs
- Refresh the page to see updated status
Scheduled Execution
Pipelines with scheduled triggers run automatically without manual intervention.Configuring Schedules
When creating or editing a pipeline, select Scheduled as the trigger type and provide a cron expression: Common Schedules:0 0 * * *- Daily at midnight0 2 * * *- Daily at 2 AM0 */6 * * *- Every 6 hours0 9 * * 1-5- Weekdays at 9 AM0 0 1 * *- First day of each month at midnight
Scheduled pipelines must be in Active status to run automatically. Paused or Draft pipelines won’t execute on schedule.
Managing Scheduled Pipelines
To control scheduled execution:- Pause - Temporarily disable automatic runs (pipeline remains deployed)
- Activate - Re-enable automatic runs
- Edit Schedule - Modify the cron expression through trigger settings
Managing Pipeline Status
Learn how to pause and activate pipelines
Event-Driven Execution
Event-driven pipelines run automatically when specific events occur, such as:- New data detected in source systems
- External API calls or webhooks
- Completion of upstream pipelines
- Manual triggers from external systems
Event-driven execution requires additional configuration with your Collector and may not be available for all data sources. Contact your administrator for setup assistance.
Execution Monitoring
Understanding Status Indicators
Pipeline completed without errors. All data types processed successfully.
Pipeline is currently executing. Check back for completion status.
Pipeline encountered errors during execution. Review logs for details.
Pipeline is queued for execution but hasn’t started yet.
Execution Metrics
Key metrics to monitor: Execution Time- How long the pipeline took to complete
- Helps identify performance issues or bottlenecks
- Rows read from each source
- Rows written to each data type
- Helps validate data volumes
- Percentage of successful vs. failed runs
- Indicator of pipeline stability
- When the pipeline last executed
- Helps verify schedules are working
Force Run vs. Incremental Run
Force Run (Full Refresh)
Processes all data from sources, regardless of when it was last processed. Use for:- Initial pipeline deployment
- After structural changes to mappings
- Recovery from errors
- Data quality fixes
Incremental Run (Default)
Processes only new or changed data since the last successful run. Use for:- Regular scheduled executions
- Efficient ongoing data synchronization
- Minimizing processing time and costs
Incremental processing requires proper configuration of change tracking or timestamp fields in your source data.
Troubleshooting Pipeline Runs
Pipeline Won’t Start
Problem: Clicking Run doesn’t start execution. Solutions:- Verify pipeline is deployed (not in Draft status)
- Check if pipeline is already running
- Ensure you have run permissions
- Verify Collector sources are connected and accessible
Pipeline Fails Immediately
Problem: Pipeline status changes to Failed within seconds. Solutions:- Review error logs for specific error messages
- Verify source connections are active
- Check for missing required field mappings
- Ensure data types have valid configurations
- Run in dry-run mode to isolate issues
Pipeline Runs Too Long
Problem: Pipeline takes much longer than expected. Solutions:- Check source data volumes (unexpected growth?)
- Review field mappings for inefficient transformations
- Verify source queries don’t have missing filters
- Consider breaking into smaller pipelines
- Check for network or database performance issues
Pipeline Succeeds But Data Is Wrong
Problem: Pipeline completes successfully but data doesn’t look right. Solutions:- Run in dry-run mode and examine query logic
- Verify field mappings are pointing to correct source fields
- Check transformation logic (COALESCE, CONCAT, CASE)
- Review default values for unexpected overrides
- Validate source data quality
Dry Run Succeeds, Standard Run Fails
Problem: Dry run works but standard run encounters errors. Solutions:- Check warehouse permissions and write access
- Verify storage quotas haven’t been exceeded
- Review data type constraints in warehouse schema
- Check for concurrent processes causing locks
- Examine differences in dry-run vs. standard execution paths
Best Practices
Execution Frequency Guidelines
Daily Pipelines
Best for data that changes frequently and needs to be current:- Client and account information
- Transaction data
- Daily metrics and KPIs
Weekly Pipelines
Best for less time-sensitive data or data-intensive processes:- Historical aggregations
- Complex analytical calculations
- Archive and cleanup operations
Monthly Pipelines
Best for periodic reporting data:- Month-end calculations
- Historical trend analysis
- Regulatory reporting data
On-Demand Pipelines
Best for ad-hoc or conditional processing:- Data migrations
- Backfill operations
- Testing and development
- Manual data corrections
Related Topics
Deploying Pipelines
Learn how to deploy pipelines before running
Managing Status
Control pipeline active/paused status
Creating Pipelines
Set up pipelines with proper triggers
Data Mapping
Configure mappings that pipelines execute